3.2.3 : Storing Merger Trees
|
Many of the questions in the previous section require retrieval of the merger history,
be it of halos or of galaxies.
A straightforward way to store a tree structure such as the merger trees here, where
each halo has at most one descendant is to create a foreign key from each halo to
its descendant. Though this is the most explicit way to store the trees as well
as the most efficient in terms of space requirements, the problem is that one requires recursive
methods to retrieve information about a complete tree. While some database systems have explicit
support for recursive queries, for example DB2, it will still be very inefficient, when the
trees are deep, to retrieve them using such queries.
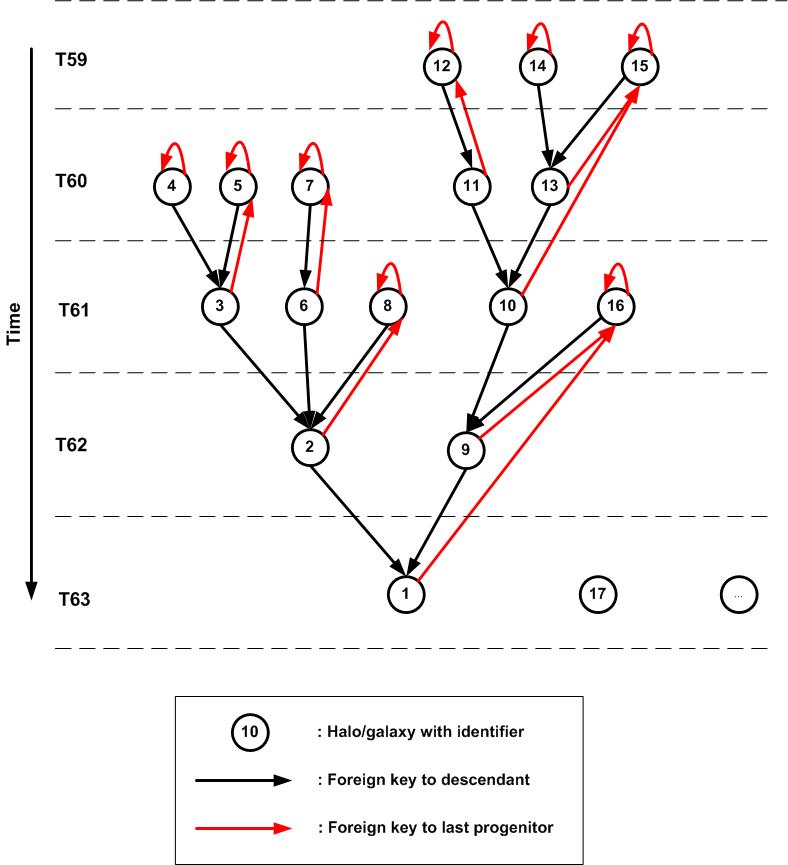
To support efficient retrieval of complete trees rooted in a halo at the final output time, one might add a foreign key to each halo pointing to the final descendant in its tree in addition to the direct descendant. This however does not help us to retrieve trees rooted in halos at other timestamps, which is something we also want to be able to do. And it becomes very expensive to add foreign keys to each descendant at later times for all halos. Instead we have implemented an alternative model which provides very quick retrieval of complete trees, rooted in any halo, using completely standard SQL. The central idea is to store the nodes of a tree in the order they are visited in a depth-first search, starting with the root of a tree and following the descendant edges in opposite direction. The nodes of the tree (halos or galaxies) get unique integer identifiers that give the rank in the resulting sort added to the identifier of the root. In Fig. 2 this is illustrated.
Every halo gets, in addition to the descendant foreign key, a foreign key pointing to the "last progenitor". The last progenitor is that progenitor that comes last in the sort. It is easy to see that this implies that the tree rooted in a certain node contains precisely those nodes with identifier values BETWEEN (in the SQL sense) the identifier of the root and that of the last progenitor. To improve the efficiency of these retrievals we define an index on the identifier and order the table on disk acording to this index. This implies that the merger tree rooted in a certain tree node is located on disk directly following the node itself, which ensures very fast retrieval times, requiring only a few consecutive page reads. |